 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan Zhang
MoE-TinyMed: Mixture of Experts for Tiny Medical Large Vision-Language Models
Apr 16, 2024
Mixture of Expert Tuning (MoE-Tuning) has effectively enhanced the performance of general MLLMs with fewer parameters, yet its application in resource-limited medical settings has not been fully explored. To address this gap, we developed MoE-TinyMed, a model tailored for medical applications that significantly lowers parameter demands. In evaluations on the VQA-RAD, SLAKE, and Path-VQA datasets, MoE-TinyMed outperformed LLaVA-Med in all Med-VQA closed settings with just 3.6B parameters. Additionally, a streamlined version with 2B parameters surpassed LLaVA-Med's performance in PathVQA, showcasing its effectiveness in resource-limited healthcare settings.
Joint Visual and Text Prompting for Improved Object-Centric Perception with Multimodal Large Language Models
Apr 06, 2024Multimodal Large Language Models (MLLMs) such as GPT-4V and Gemini Pro face challenges in achieving human-level perception in Visual Question Answering (VQA), particularly in object-oriented perception tasks which demand fine-grained understanding of object identities, locations or attributes, as indicated by empirical findings. This is mainly due to their limited capability to effectively integrate complex visual cues with textual information and potential object hallucinations. In this paper, we present a novel approach, Joint Visual and Text Prompting (VTPrompt), that employs fine-grained visual information to enhance the capability of MLLMs in VQA, especially for object-oriented perception. VTPrompt merges visual and text prompts to extract key concepts from textual questions and employs a detection model to highlight relevant objects as visual prompts in images. The processed images alongside text prompts are subsequently fed into MLLMs to produce more accurate answers. Our experiments with GPT-4V and Gemini Pro, on three benchmarks, i.e., MME , MMB and POPE, demonstrate significant improvements. Particularly, our method led to a score improvement of up to 183.5 for GPT-4V on MME and enhanced MMB performance by 8.17\% for GPT-4V and 15.69\% for Gemini Pro.
Quantifying and Mitigating Unimodal Biases in Multimodal Large Language Models: A Causal Perspective
Apr 03, 2024
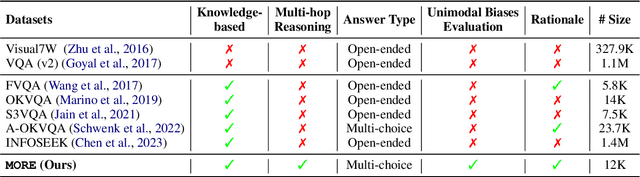
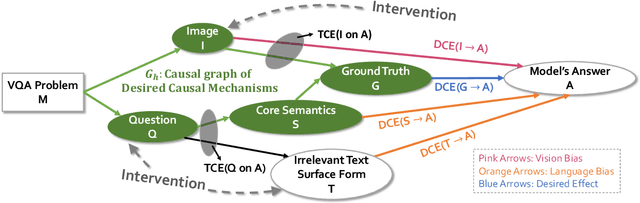

Recent advancements in Large Language Models (LLMs) have facilitated the development of Multimodal LLMs (MLLMs). Despite their impressive capabilities, MLLMs often suffer from an over-reliance on unimodal biases (e.g., language bias and vision bias), leading to incorrect answers in complex multimodal tasks. To investigate this issue, we propose a causal framework to interpret the biases in Visual Question Answering (VQA) problems. Within our framework, we devise a causal graph to elucidate the predictions of MLLMs on VQA problems, and assess the causal effect of biases through an in-depth causal analysis. Motivated by the causal graph, we introduce a novel MORE dataset, consisting of 12,000 VQA instances. This dataset is designed to challenge MLLMs' abilities, necessitating multi-hop reasoning and the surmounting of unimodal biases. Furthermore, we propose two strategies to mitigate unimodal biases and enhance MLLMs' reasoning capabilities, including a Decompose-Verify-Answer (DeVA) framework for limited-access MLLMs and the refinement of open-source MLLMs through fine-tuning. Extensive quantitative and qualitative experiments offer valuable insights for future research. Our project page is at https://opencausalab.github.io/MORE.
RELI11D: A Comprehensive Multimodal Human Motion Dataset and Method
Mar 28, 2024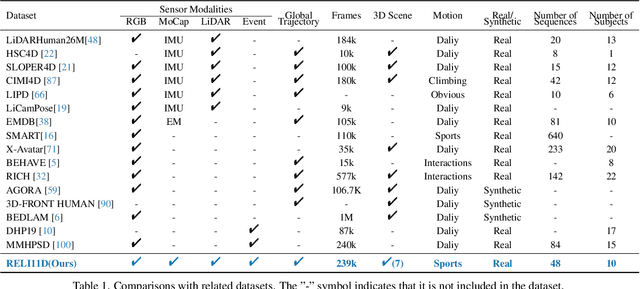

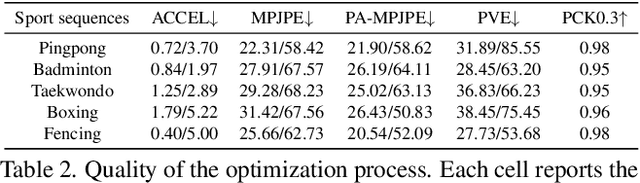

Comprehensive capturing of human motions requires both accurate captures of complex poses and precise localization of the human within scenes. Most of the HPE datasets and methods primarily rely on RGB, LiDAR, or IMU data. However, solely using these modalities or a combination of them may not be adequate for HPE, particularly for complex and fast movements. For holistic human motion understanding, we present RELI11D, a high-quality multimodal human motion dataset involves LiDAR, IMU system, RGB camera, and Event camera. It records the motions of 10 actors performing 5 sports in 7 scenes, including 3.32 hours of synchronized LiDAR point clouds, IMU measurement data, RGB videos and Event steams. Through extensive experiments, we demonstrate that the RELI11D presents considerable challenges and opportunities as it contains many rapid and complex motions that require precise location. To address the challenge of integrating different modalities, we propose LEIR, a multimodal baseline that effectively utilizes LiDAR Point Cloud, Event stream, and RGB through our cross-attention fusion strategy. We show that LEIR exhibits promising results for rapid motions and daily motions and that utilizing the characteristics of multiple modalities can indeed improve HPE performance. Both the dataset and source code will be released publicly to the research community, fostering collaboration and enabling further exploration in this field.
Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives
Mar 26, 2024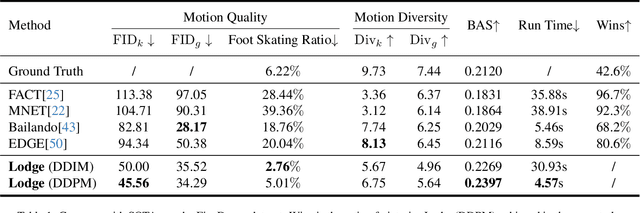
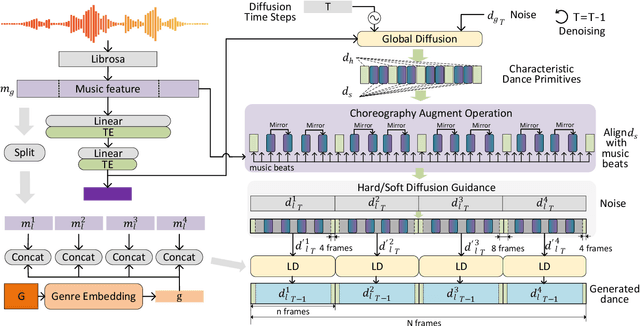
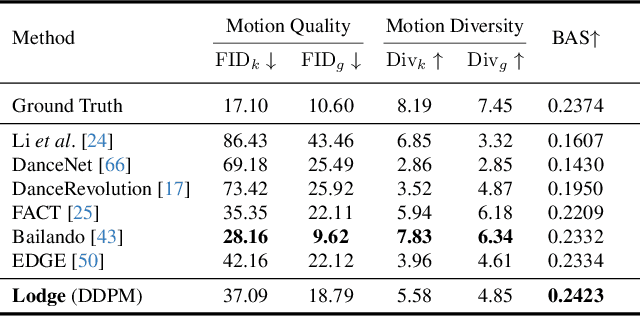
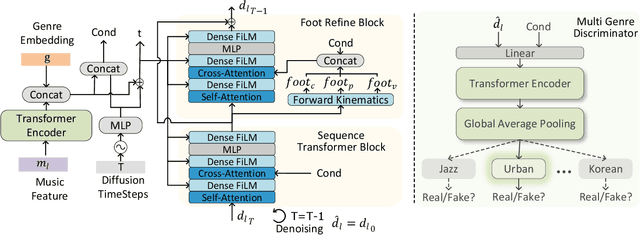
We propose Lodge, a network capable of generating extremely long dance sequences conditioned on given music. We design Lodge as a two-stage coarse to fine diffusion architecture, and propose the characteristic dance primitives that possess significant expressiveness as intermediate representations between two diffusion models. The first stage is global diffusion, which focuses on comprehending the coarse-level music-dance correlation and production characteristic dance primitives. In contrast, the second-stage is the local diffusion, which parallelly generates detailed motion sequences under the guidance of the dance primitives and choreographic rules. In addition, we propose a Foot Refine Block to optimize the contact between the feet and the ground, enhancing the physical realism of the motion. Our approach can parallelly generate dance sequences of extremely long length, striking a balance between global choreographic patterns and local motion quality and expressiveness. Extensive experiments validate the efficacy of our method.
Graph Neural Networks for Learning Equivariant Representations of Neural Networks
Mar 20, 2024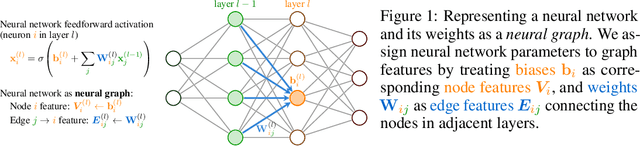
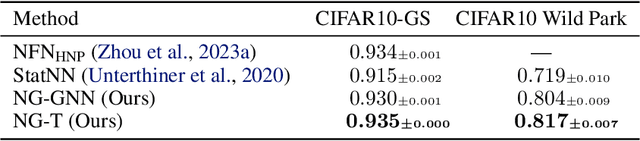
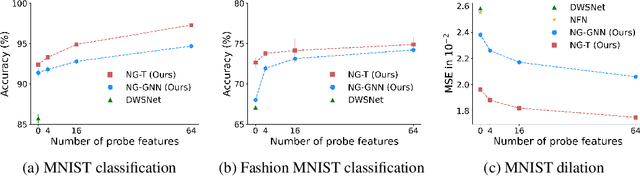

Neural networks that process the parameters of other neural networks find applications in domains as diverse as classifying implicit neural representations, generating neural network weights, and predicting generalization errors. However, existing approaches either overlook the inherent permutation symmetry in the neural network or rely on intricate weight-sharing patterns to achieve equivariance, while ignoring the impact of the network architecture itself. In this work, we propose to represent neural networks as computational graphs of parameters, which allows us to harness powerful graph neural networks and transformers that preserve permutation symmetry. Consequently, our approach enables a single model to encode neural computational graphs with diverse architectures. We showcase the effectiveness of our method on a wide range of tasks, including classification and editing of implicit neural representations, predicting generalization performance, and learning to optimize, while consistently outperforming state-of-the-art methods. The source code is open-sourced at https://github.com/mkofinas/neural-graphs.
CrossTune: Black-Box Few-Shot Classification with Label Enhancement
Mar 19, 2024

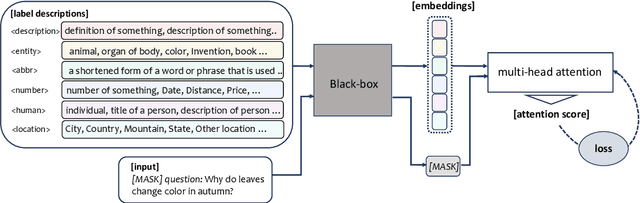
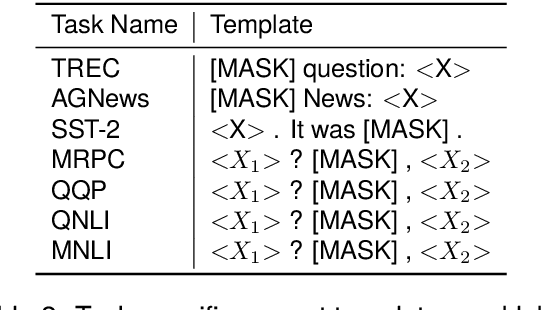
Training or finetuning large-scale language models (LLMs) requires substantial computation resources, motivating recent efforts to explore parameter-efficient adaptation to downstream tasks. One approach is to treat these models as black boxes and use forward passes (Inference APIs) to interact with them. Current research focuses on adapting these black-box models to downstream tasks using gradient-free prompt optimization, but this often involves an expensive process of searching task-specific prompts. Therefore, we are motivated to study black-box language model adaptation without prompt search. Specifically, we introduce a label-enhanced cross-attention network called CrossTune, which models the semantic relatedness between the input text sequence and task-specific label descriptions. Its effectiveness is examined in the context of few-shot text classification. To improve the generalization of CrossTune, we utilize ChatGPT to generate additional training data through in-context learning. A switch mechanism is implemented to exclude low-quality ChatGPT-generated data. Through extensive experiments on seven benchmark text classification datasets, we demonstrate that our proposed approach outperforms the previous state-of-the-art gradient-free black-box tuning method by 5.7% on average. Even without using ChatGPT-augmented data, CrossTune performs better or comparably than previous black-box tuning methods, suggesting the effectiveness of our approach.
Boosting Disfluency Detection with Large Language Model as Disfluency Generator
Mar 13, 2024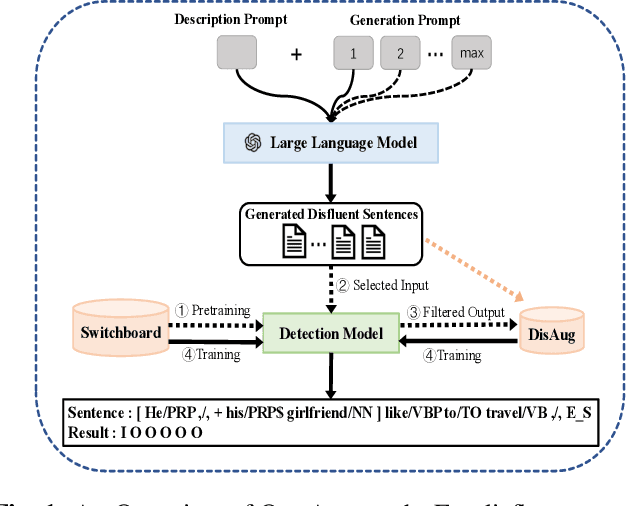

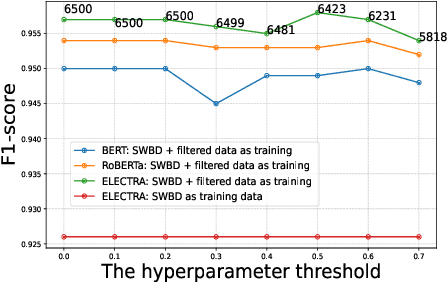
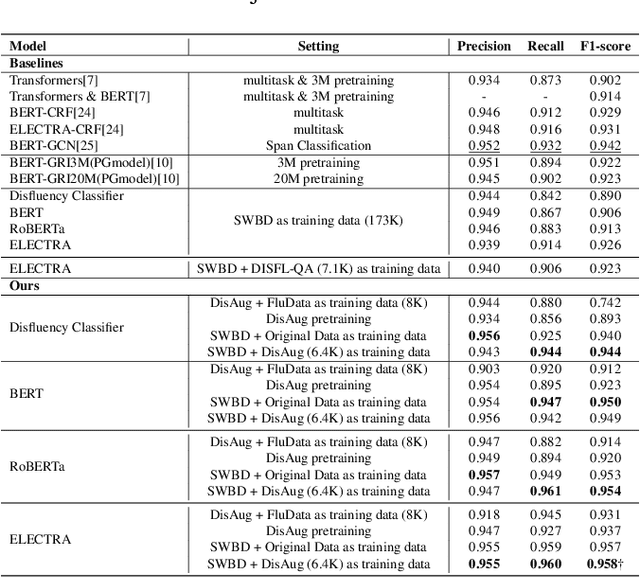
Current disfluency detection methods heavily rely on costly and scarce human-annotated data. To tackle this issue, some approaches employ heuristic or statistical features to generate disfluent sentences, partially improving detection performance. However, these sentences often deviate from real-life scenarios, constraining overall model enhancement. In this study, we propose a lightweight data augmentation approach for disfluency detection, utilizing the superior generative and semantic understanding capabilities of large language model (LLM) to generate disfluent sentences as augmentation data. We leverage LLM to generate diverse and more realistic sentences guided by specific prompts, without the need for fine-tuning the LLM. Subsequently, we apply an uncertainty-aware data filtering approach to improve the quality of the generated sentences, utilized in training a small detection model for improved performance. Experiments using enhanced data yielded state-of-the-art results. The results showed that using a small amount of LLM-generated enhanced data can significantly improve performance, thereby further enhancing cost-effectiveness.
Graph Neural Network with Two Uplift Estimators for Label-Scarcity Individual Uplift Modeling
Mar 11, 2024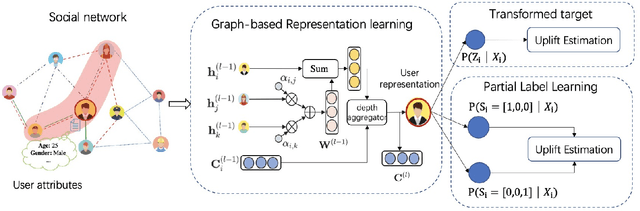

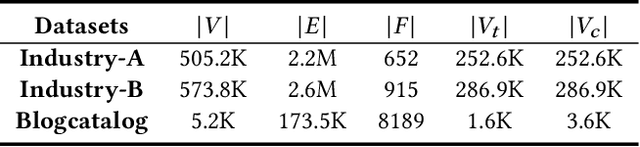

Uplift modeling aims to measure the incremental effect, which we call uplift, of a strategy or action on the users from randomized experiments or observational data. Most existing uplift methods only use individual data, which are usually not informative enough to capture the unobserved and complex hidden factors regarding the uplift. Furthermore, uplift modeling scenario usually has scarce labeled data, especially for the treatment group, which also poses a great challenge for model training. Considering that the neighbors' features and the social relationships are very informative to characterize a user's uplift, we propose a graph neural network-based framework with two uplift estimators, called GNUM, to learn from the social graph for uplift estimation. Specifically, we design the first estimator based on a class-transformed target. The estimator is general for all types of outcomes, and is able to comprehensively model the treatment and control group data together to approach the uplift. When the outcome is discrete, we further design the other uplift estimator based on our defined partial labels, which is able to utilize more labeled data from both the treatment and control groups, to further alleviate the label scarcity problem. Comprehensive experiments on a public dataset and two industrial datasets show a superior performance of our proposed framework over state-of-the-art methods under various evaluation metrics. The proposed algorithms have been deployed online to serve real-world uplift estimation scenarios.
Benchmarking Micro-action Recognition: Dataset, Methods, and Applications
Mar 08, 2024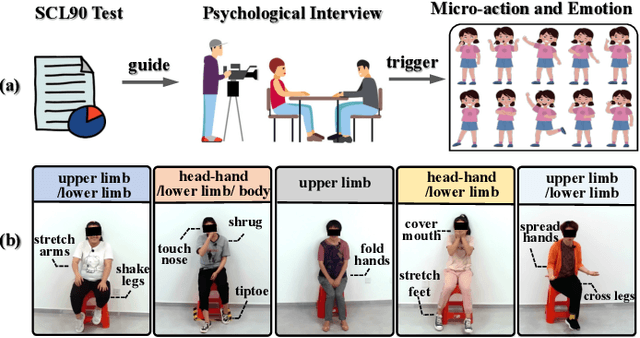
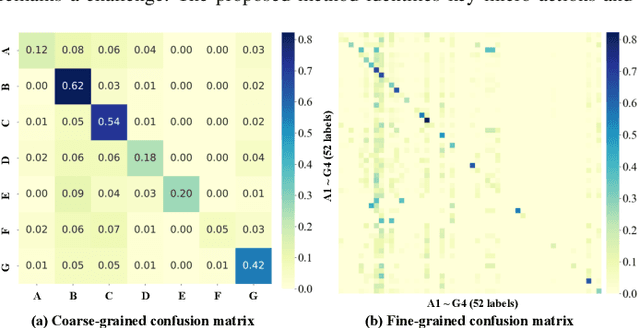
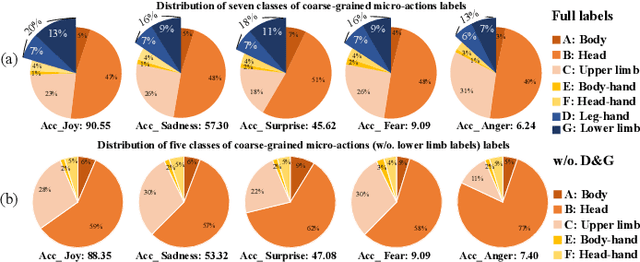
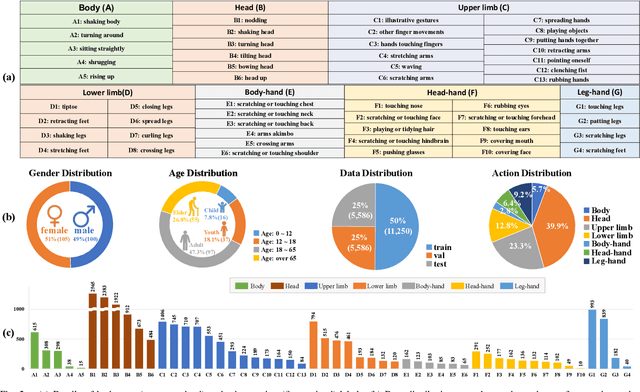
Micro-action is an imperceptible non-verbal behaviour characterised by low-intensity movement. It offers insights into the feelings and intentions of individuals and is important for human-oriented applications such as emotion recognition and psychological assessment. However, the identification, differentiation, and understanding of micro-actions pose challenges due to the imperceptible and inaccessible nature of these subtle human behaviors in everyday life. In this study, we innovatively collect a new micro-action dataset designated as Micro-action-52 (MA-52), and propose a benchmark named micro-action network (MANet) for micro-action recognition (MAR) task. Uniquely, MA-52 provides the whole-body perspective including gestures, upper- and lower-limb movements, attempting to reveal comprehensive micro-action cues. In detail, MA-52 contains 52 micro-action categories along with seven body part labels, and encompasses a full array of realistic and natural micro-actions, accounting for 205 participants and 22,422 video instances collated from the psychological interviews. Based on the proposed dataset, we assess MANet and other nine prevalent action recognition methods. MANet incorporates squeeze-and excitation (SE) and temporal shift module (TSM) into the ResNet architecture for modeling the spatiotemporal characteristics of micro-actions. Then a joint-embedding loss is designed for semantic matching between video and action labels; the loss is used to better distinguish between visually similar yet distinct micro-action categories. The extended application in emotion recognition has demonstrated one of the important values of our proposed dataset and method. In the future, further exploration of human behaviour, emotion, and psychological assessment will be conducted in depth. The dataset and source code are released at https://github.com/VUT-HFUT/Micro-Action.